2022-11-03
Many have become familiar with the quasi user interface of Copilot and related code assistant tools. You provide context for a task, some definitions and examples, followed by a cue for Copilot to generate something, often in the form of a comment. Competing products have shown a more explicit interface, such as a dialog box, but for purposes of this exploration I don't think they function differently.
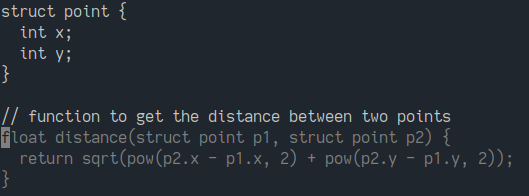
Copilot's capabilities have been widely explored elsewhere; It suffices to say it exceeded my own expecations and those of everyone I've shown it to. At the same time, with only a few days' use it becomes apparent that the tecnology's full metaprogramming potential is underutilized in its current interface:
Over the weekend I performed a limited experiment to remedy these problems. I doubt I'm the first to do any of this, but I didn't quickly find others descirbing these techniques.
Immediate goals for improvement were:
Copilot's terms of service don't appear to explicitly prohibit automated use. I suspect this grey area will be clarified in the future. It looks like OpenAI wants to charge lots of money to use Codex as a service. I'm sure enterprise products using these models for code generation will emerge quickly. For now, this is only my experiment, and I can't guarantee it will remain viable.
With no public API for Copilot, I instead automated the editor by sending it keyboard inputs:
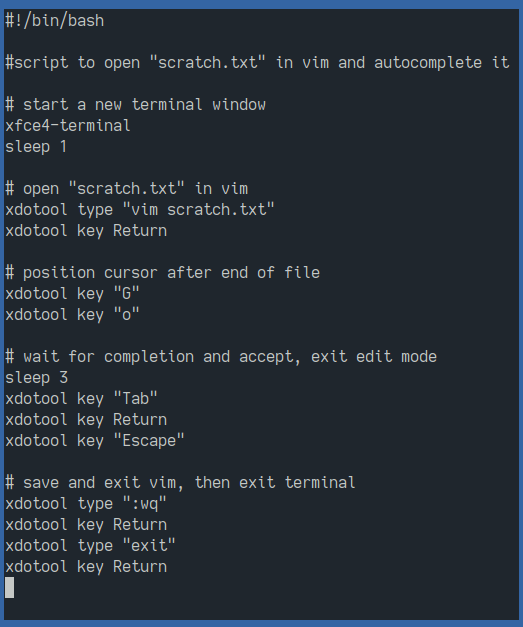
I tried Vimscript but I don't think it can emulate pressing the tab key.
To ask Copilot to do something, you append a query prompt to your document along with a cue to generate an answer. Write this to a temporary file. The script opens Vim, loads the file, and positions the cursor at the end of the document. It waits a moment for Copilot to suggest something, then accepts the completion and saves the file. The tail of the file can then be read back to obtain the result.
This is silly, but so far works every time given sufficient timing.
Typical interaction with Copilot consists of some document context, to which we append some definitions, examples, and a cue for the model to generate a response. We then discard from the document the prompt along with any other intermediate scaffolding we're not longer interested in.
There's a natural model for this, and that's a stack machine. In a basic stack machine, data is stored as a contigous sequence of values, which grows in one direction. Instructions operate at the live end ("top") of the stack, reading preceding values as inputs and appending their outputs to the top of the stack.
For those unfamiliar, the below video steps through how arithmetic is performed using a stack. A hierarchy of operations of any depth can be represented as stack operations. Because of this, stack languages barely need to be more complicated than this toy model to accomplish real work, which makes them useful for bespoke applications. Copilot can itself generate nearly the entire implementation for a stack machine simply from a comment listing the desired instructions to be supported.
Step-by-step example of stack program evaluation.
A basic stack language for Copilot can be simple as the only data we need to start are strings, and the only strictly required operation is "tell Copilot to do something given this context." We'll add the ability to read and write files, as well as pop unwanted values from the end of the stack to avoid letting the context grow too large, which might diminish Copilot's performance.

Tiny stack language for manipulating Copilot.
The implementation is trivial; 110 lines of C++ written almost entirely by Copilot.
Here's a simple program that uses successive Copilot prompts to build up types:
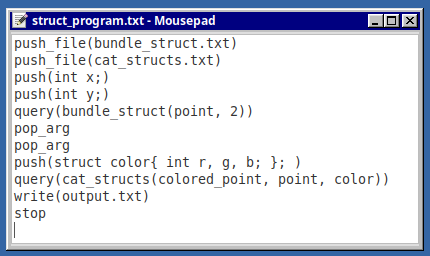
The program starts by reading a couple files, whose contents are shown below.
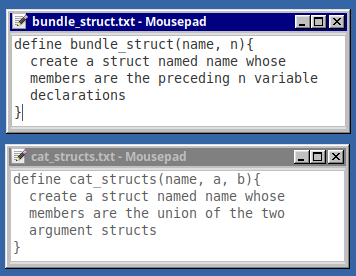
Macro-style prompt definitions consumed by Copilot.
These look like macro definitions, but with no implementation, just a psuedocode description of what we want Copilot to do. Giving these tasks a name and something resembling a function signature is a useful organizing convention and provides understandable cues for Copilot.
To use these directives, we push a couple arguments onto the stack, then cue Copilot with something that looks like a function call. The task is simple and Copilot does what we want. The result is pushed onto the stack and we can discard the preceding argument values. We can then repeat the process to build up a more complex type.
Below is a walkthrough showing the state of the stack through the program. I
omit generation of the temporary scratch file; all that happens is the contents
of the stack are interleaved with a separator ("// ----"), the
query is appended, the script is run, and whatever Copilot produces gets read
back in and pushed to the stack.
Step-by-step walkthrough of the struct program.
This program builds up functions in a similar way:
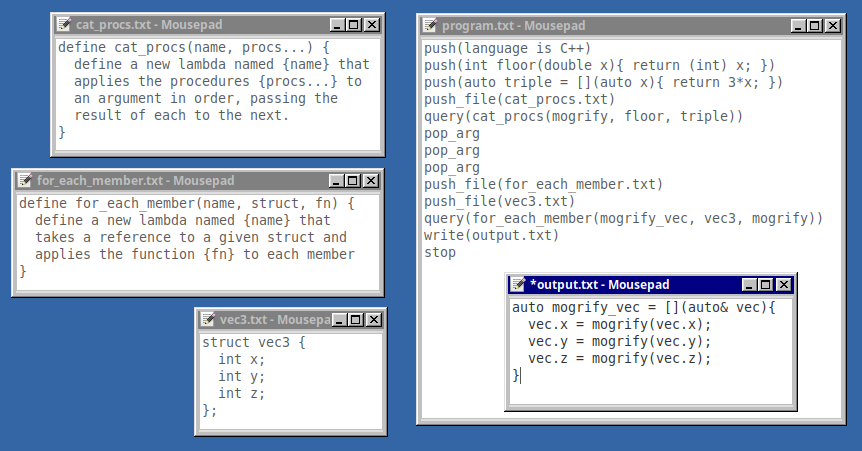
Stack program that produces function definitions.
Here Copilot correctly uses a variadic macro definition with multiple arguments to be provided later. The language cue at the top is necessary with tiny contexts as Copilot sometimes defaults to generating Python lambda expressions despite the C++ syntax in the context.
It took several attempts to get the "for_each_member" directive right. Copilot strongly prefers generating functions that accept and return by value, rather than use a mutable reference parameter to modify an external object. A potential advantage of manipulating Copilot with structured input is once a working prompt is found, it can be resued in multiple contexts. This is taking the work of "prompt engineering" and resuing it like library functions.
A task I desired of intermediate complexity was generating type erasure classes. The input to this task is an interface (set of function signatures) and the output is a nested class definition that implements that interface, as well as a nested template class which implements dynamic dispatch. Knowing how this works is not required, it's just a lot of boilerplate. A file is provided to Copilot as an example of what we want.
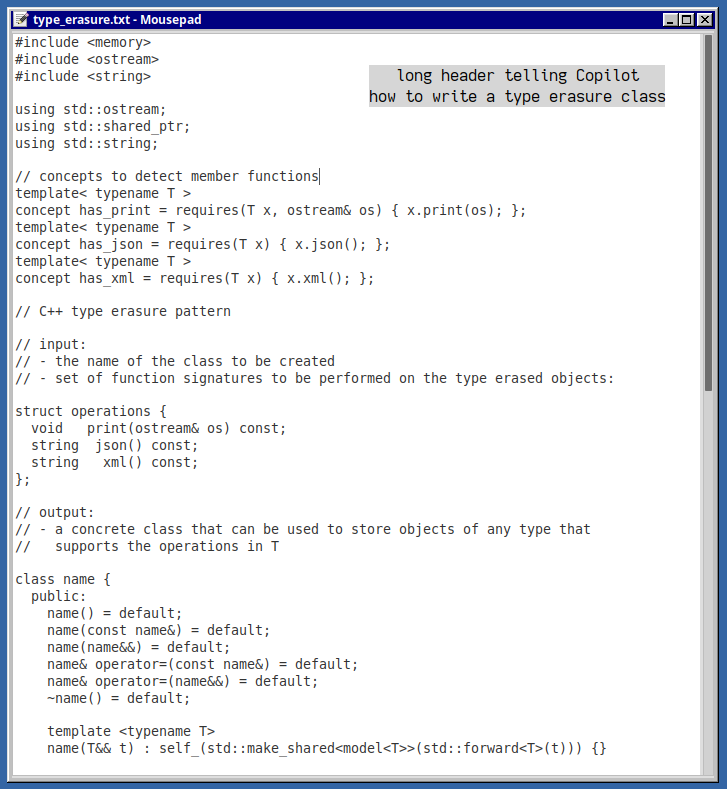
Type erasure class "library header".
Copilot has seen versions of this pattern before and can generate a basic instance of it in one prompt, but I wanted to add an additional feature (automatic switching between free and member functions) which complicated it somewhat. Additional definitions (C++20 concepts) were required outside the class body, which went against Copilot's strong preference for generating self-contained top-level entities. Additional condition checks would also grow the total size of the class.
Breaking the task into smaller steps worked, with a separate prompt for each top-level entity to be generated. To assist with building up larger output, an interpreter instruction was added to concatenate stack values. The implementation of this function was, of course, generated by Copilot from a short description in the instruction table, which it also wrote.
Below, the first part of the program generates concept definitions from function signatures. The hint that we are looking for single-line output assists in getting a complete answer with only one tab completion. Copilot continues to impress with its ability to follow a pattern given only a single example, which can be reused like "library" code.
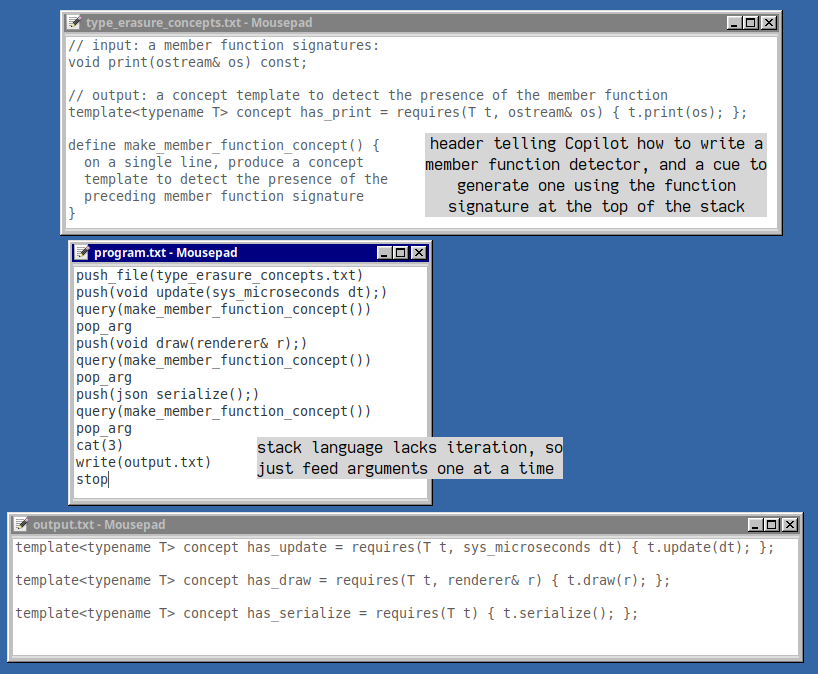
With those definitions on the stack, Copilot then reliably used them to generate the entire class definition in one prompt, with desired modifications:
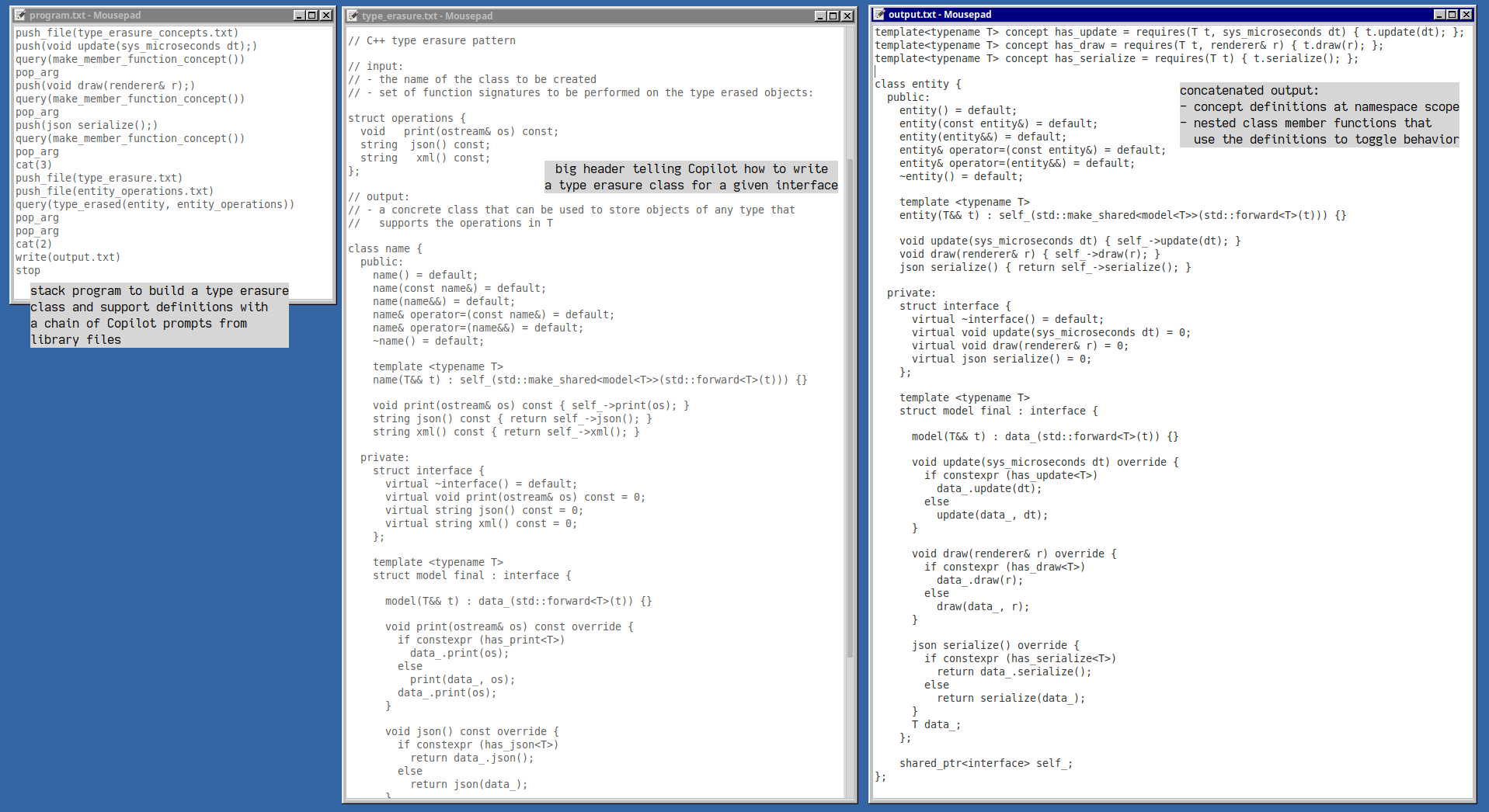
Complicated class definition generated by Copilot.
I only tested one run's output, but it compiled with no edits.
Copilot can write structured prompts for itself:
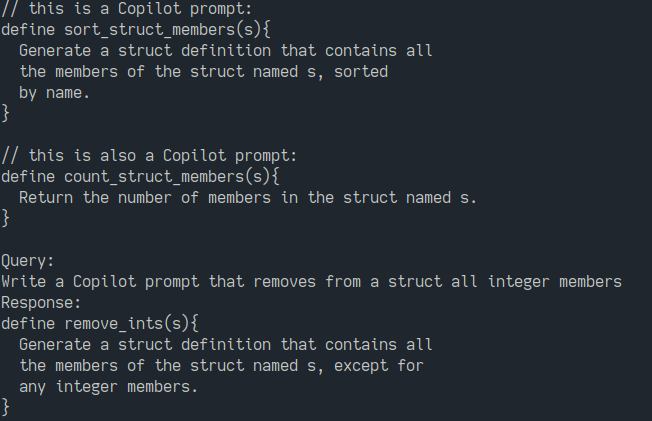
Copilot writing a simple prompt for itself.
To try and make a prompt more interesting than a mere restatement of the query text, I tried teaching Copilot to use higher-order macros that bind variables from the context into a new prompt definition.
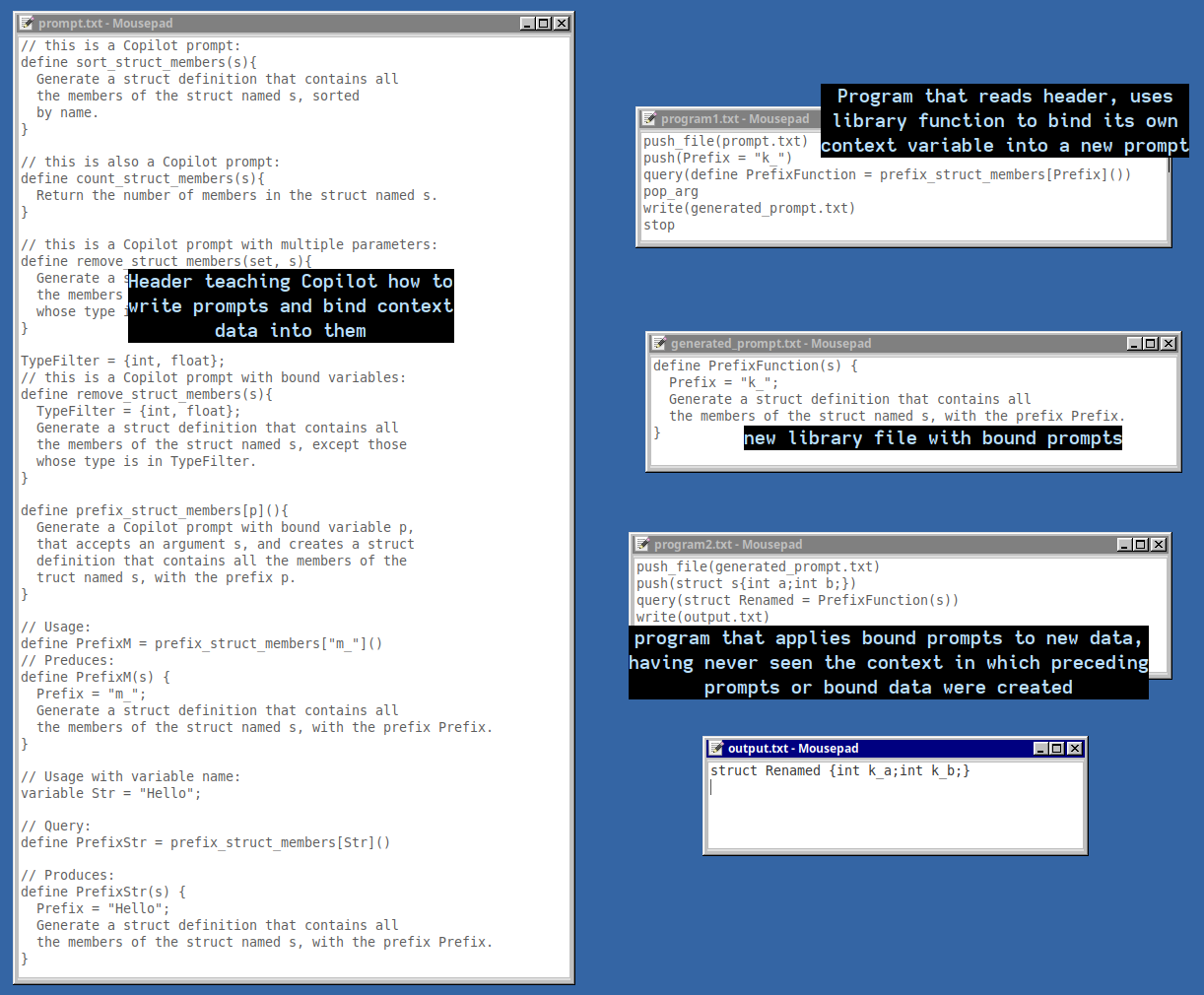
Copilot writing a new prompt with bound data from context.
It does a decent job with it. The applications of a psuedo lambda expression are apparent, but in particular for Copilot, it allows the creation of specialized prompts from runtime data that contain only the information needed to complete a specifc task. All the preceding training that went into building it can be discarded, and the prompt reused in other contexts.
This encapsulation is important as Copilot's context for any given suggestion is limited; Reportedly about 2k tokens are used, with some context coming from a small list recently used files. Increasing the information density of this small context is requried for such a tool to be applied to larger programs. Higher-order prompts can package runtime data, or the result of a longer prompt dialog, into a named abstraction that can be recalled in other contexts.
Copilot adapts easily to new tasks and languages. Given a custom C++ library for manipulating DOM elements from WASM, Copilot correctly used it to build up hierarchical structures, attach event handlers, and so on, despite not having examples for all the new combinations it was suggesting. The paucity of information specific to a new context is augmented by the wealth of domain knowledge the model brings with it to new task.
Copilot is capable of suggesting code in our new language, too:
Copilot suggesting stack code from a higher level prompt.
This works despite the fact that Copilot has never seen this new language used in relation to an "alpha channel" before. It already knows what graphics code looks like, and only needs to figure out this new way of manipulating data types.
Given a small amount of example context and a text prompt, Copilot correctly generates more stack instructions to create more code, then combine and write results as appropriate to build up header and source files.
Copilot suggesting stack code to build up source files.
I expect others are already making a product that does basically this without the user pressing the tab key in between each line and running a fragile shell script to send data through Vim. Expect it to be soon possible to say "write a test stub for every public function of this class" and see a bunch of new files appear in your IDE sidebar.
Freed from the constraints of the tab completion interface, Copilot reveals itself to be a powerful tool for generating code, not just in the form of longer text completion, but self-direction to perform sequences of actions across multiple files, reusing its own output. This technology's application as mere auto-completion tool emitting code line by line at human direction will soon seem an antiquated interface.
The examples shown are pushing up against the limits of how much Copilot is willing to generate through tab-completion suggestions. Given its proven success with structured tasks, I don't doubt that the current model behind the scenes is capable of generating many hundreds of lines of simple code at once if it were configured to do so.
As shown, the limitations of Copilot's current output constraints can be worked around by breaking a task into smaller steps, then combining results with non-ML text manipulation (insertion, duplication, concatenation, etc). But if you're going to do that much text wrangling, you might as well just write parsers and generators for the code you want to produce. These run fast, are more reliable, and as it turns out, Copilot is adept at writing them for you, which it only has to do once.
For unattended use, Copilot is underutilized as an expensive, slow, glorified macro processor. The more practical applications will involve models that output higher-level directives for larger workflows, perhaps with less of the lower level text generation being done by what are for now comparatively expensive ML tools.
You probably shouldn't try using this for anything serious. Someone with access to the paid Codex API could make a better version of it. My rough estimation from published pricing is that using Codex programmatically with a few hundred lines of context input, and some bulky output, could approach a dollar per invocation depending on quality settings. I assume ML experts know how to iterate on output without re-consuming the entire surrounding context, but this might not be possible with the present API.
Compared to public pricing for text models, Copilot is cheap at $100/yr, so cheap I wonder if it's being operated at a loss. If it is expect a heavy crackdown on any serious programmatic use, which will eventually arrive as a commercial product with significant fees.
I thought it would be cool to end with a video of the Game of Life running in the stack machine, but estimated that it would take a couple hours to advance one generation of an 8x8 game grid at the minimum possible script timing. Sorry folks; if anyone wants to risk getting their account banned performing such an inefficient use of compute resources, you can try it yourself.