2023-10-10
Functions often do work with information not known until run time:
// scale some values by a common factor
void multiply(vector& Values, const int Factor){
for( auto& V : Values ) { V = V * Factor; } imul edx, esi
} This function doesn't know the value being multiplied until it is called. The compiler (gcc, O2) emits a generic integer multiply instruction in its loop body.
Sometimes we know a better way to handle certain cases, and act on this explicitly:
// same function signature as before
void multiply(vector& Values, const int Factor){
if( Factor == 2 ){
// multiplying by two is the same as shifting by one
for( auto& V : Values ) { V = V << 1; } sal [rax]
} else {
// default implementation for any value
for( auto& V : Values ) { V = V * Factor; } imul edx, esi
}
} The function does the same work, but will use a faster method for certain arguments, without users having to opt-in to a better version.
The condition check has to be up front, outside the loop. Checks within loops are less helpful or even harmful:
for( auto& V : Values ){
if( Factor == 2 ){
V = V << 1;
} else {
V = V * Factor;
}
}This example is contrived, but the pattern arises naturally, because our default thinking is first of algorithmic iteration, then of case handling. Last-minute decision-making thus creeps into code.
Compilers try to hoist constant conditions outside of loops but they're bad at it. Even in the trivial example above, on -O2 gcc does a redundant check with every loop iteration.
Using precondition checks to dispatch to different implementations at run time is great if you know a certain technique applies. But the observation that motivates this post is adding special cases can improve code generation even when the implementation in each branch is identical:
void multiply(vector& Values, const int Factor){
if( Factor == 2 ){
// no special handling; just multiplies
for( auto& V : Values ) { V = V * Factor; } sal [rax]
} else {
// identical loop body to above
for( auto& V : Values ) { V = V * Factor; } imul edx, esi
}
} View these examples on Compiler Explorer
All we did was copy the source code, but the compiler has converted the multiply to a shift for us in the appropriate branch.
I emphasize this is not a static branch (if constexpr),
constant value, or call-site specific optimization. It is a regular run time if
statement, branching on the value of an opaque function argument. But its
existence has added an opportunity at compile time to exploit information we
anticipate to have at run time.
Compilers will try to add their own fast path handling to your code to take advantage of run time information, such as for autovectorization. But compilers lack knowledge of the distribution of expected values for your application, and are limited to generic checks likely to pay off. By adding a branch ourselves, we have brought into existence a code path in which certain conditions will always be true, that can be optimized accordingly.
An advantage of this method is that we're giving the compiler an opportunity to do something better without forcing it. Programmers often put in speed hacks based on performance knowledge which is outdated or inapplicable to the target platform. Separating cases lets the programmer supply their high-level knowledge about what values are likely to be encountered, which the compiler can optimize to the platform based on its low-level information.
For this to work, the value being used in the if statement should be
directly used later in the branch. So if( X == 42 ) provides an
easy optimization opportunity if X is directly used later. But
the compiler often does nothing if there's any indirection - if( X*2 ==
84) does not provide the same cue to do something useful.
For values known at compile time, we could get a specialized implementation for each use with a template. But templates have their drawbacks. We might not want separate code generation for every combination of parameters, only a few cases we detect. Properties that are unchanging at run time might not be part of an object's static information for a template to access. Templates in headers for an API are frustrating to use compared single functions. For these reasons it is often preferred to have one function which dispatches to different implementations internally to take advantage of run time knowledge.
I came across this technique when speeding up a simple nearest-neighbor scaling function, which composits one 2D buffer of dynamic size into another. Any combination of source/destination size is supported, but a common usage is upscaling small images by an integer ratio:
Starting with a naive version assembled from convenience functions, I gained speed from manual inlining and hoisting, and specializing for an integer ratio upscale. But it was still annoyingly slow, particularly when filling a larger window at the highest multiple.
Base integer upscale implementation
It is not necessary you follow this closely.
Without changing anything else, I added a check for the case of a 4x ratio, with the same implementation copied in both branches:
// ... const int ratio_y = d_h/s_h; const int ratio_x = d_w/s_w; if( ratio_x == 4 && ratio_y == 4 ){ // remainder of stock integer upscale implementation } else { // identical code copied here } // ...
This simple change made the 4x scaling several times faster at the O2 optimization level:
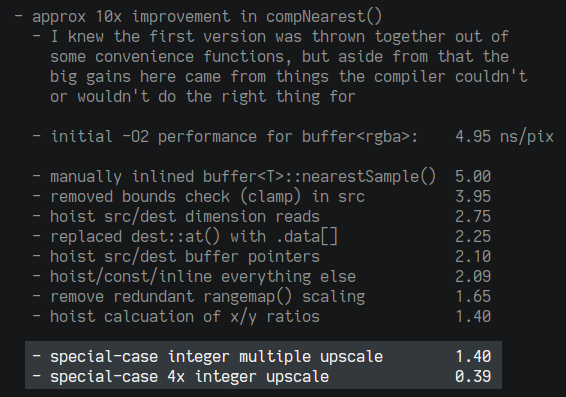
Notes from optimization attempts
Overall this was a 10x improvement, which was good enough so I didn't investigate much further. Recreating this test and doing more rigorous timing for this post, results still showed a speed up from specialization, but not as consistent:
Time for 4x 960x640 upscale
10 iterations per test
| Version | O2 | O3 |
|---|---|---|
| Default integer upscale | 500-678 µs | 438-548 µs |
| Specialization for 4x ratio | 300-320 µs | 408-436 µs |
These times are rough; Sometimes the specialization benefit disappeared.
Why is it sometimes faster? I'm still unsure. The only consistent difference I observed is a comparison against the ratio inside the loop uses a constant value in the branch where the ratio is known at compile time:
cmp instruction difference when ratio is known
const int ratio_x = d_w/s_w;
if( ratio_x == 4 ){
// known ratio
if( sc_x == ratio_x ){} cmp edx, 4
} else {
// any ratio
if( sc_x == ratio_x ){} cmp ebp, eax
}
Stripped-down example
I wrote several shorter test functions to try and exercise this difference, but none of them were faster. Published instruction tables do not show any speed difference for comparing against a constant vs. a register. A speedup may come from an interaction with branch prediction when different instructions are used. The big improvement sometimes appeared and disappeared between different runs of the same build. But it was never slower, and the specialization was worth keeping.
Forcing code separation
At O3, gcc may combine both branches into one which is faster for most values, but loses specialization for a particular value. If we want to force separation we can move each branch into a separate function or internal template with inlining prohibited.
Code can be separated in situ with an immediately invoked lambda:
if( condition ){
[&]() __attribute__ ((noinline)) {
// specialized implementation
}();
} else {
// default implementation
}
Thanks to Matt Godbolt's blog for showing where the function attribute has to be put on a lambda.
This should be done sparingly. Giving the compiler an opportunity to do something is useful, but measure carefully before forcing it.
Outside of a template, we often want to generate code to handle different possibilities. C++ lacks a general reflection mechanism for emitting switch-case code for e.g. each option of an enum, forcing use of external code generation or manual copying.
The only language tool I know that can be used to this effect is
std::visit, which uses template and macro horrors to generate an
exhaustive call site invoking a callable object for each possible alternative in a
std::variant. This can be used in combination with a generic
callable to get an otherwise impossible template-for-each construct.
Each case gets a unique instantiation which can act on static information, and presents an opportunity for separate optimization. The below example generates implementations for four variant alternatives using a generic lambda:
Case generation with std::visit
View on Compiler Explorer
struct one { constexpr static int value = 1;};
struct two { constexpr static int value = 2;};
struct three { constexpr static int value = 3;};
struct four { constexpr static int value = 4;};
using scale_factor = variant<one, two, three, four>;
void scale_vector(vector<int>& Vector, scale_factor Option){
auto Visitor = [&]<typename T>(T) __attribute__ ((noinline)) {
for( auto& V : Vector ){
V = V * T::value; // multiplies not by a variable, but a
// constant associated with the template type
}
};
visit(Visitor, Option);
}
Static information maps types to constant values, because we can only have a variant of types. These can also be used as compile-time lookup tables, such as mapping argument types to a corresponding return type.
Familiar template
syntax gives a name to the type this body is being instantiated for;
This is sometimes necessary for deducing a T which is not the same
as the argument type (e.g. the variant alternative is
foo<T>, and we wish to name the inner
T.)
The noinline attribute, included here for exposition, forces each lambda body to get a separate function for comparison. This attribute can also be used to restrict the compiler's freedom to optimize across cases that we wish to remain separate.
The argument type keys the template but doesn't need to be given a name if we aren't using the contained value at run time. It only exists to instantiate a template and facilitate lookups of compile-time information necessary for the specialization.
This function multiplies by one of four values, but because all are known and handled by unique loops, the resulting code contains no multiply instructions. Each case has been separately optimized:
lea instruction.This technique is limited to cases where std::variant is
usable, which is unfortunate because variant is a cumbersome type that is not
nice for APIs. But I have used this for systems in which a user-facing type gets
stored in a variant at a boundary, then internal operations on it use a generic
lambda to generate a unique body for each type, with each instantiation able to
statically look up associated companion types and values to use in their
implementation. This is preferable to maintaining dozens of otherwise identical
cases in a switch statement.