
2023-09-25
Topic reference links
A little-discussed method enables inserting rows with bound data into SQLite faster than any existing technique. This novel method is then discovered to have a drawback that makes it generally unusable. The rest of this article explores how to get the best insert performance out of SQLite generally; what's in your control, and what isn't. Use the links above to jump to a section, or skip to the end for the most important performance tips.
Test specs: Intel i7-9700K @ 3.60
GHz,
WD Blue SN500 NVMe SSD. SQLite version 3.37.2.
For tests of pure row insertion speed, we focus on inserting 32-bit integers into a one-column table:
CREATE TABLE integers (value INTEGER);Maximizing rows-per-second on an unindexed table, here is what is possible with the methods explained below:
Insert method comparison
| Insert method | Rows/s | |
|---|---|---|
ATTACH DATABASE (reference) |
10,684,000 | Speed limit of SQLite |
carray with unsafe PRAGMAs |
9,960,000 | |
carray |
7,968,000 | |
| bound params, unrolled insert | 7,553,000 | Best practical method |
| bound params, one row per insert | 2,701,000 |
insertion of 100M uniform 32-bit integers
The goal is to move data from an application into SQLite through some interface. To know how fast any interface could possibly go, we first ask how fast SQLite moves data internally, by using the SQLite CLI to copy directly between two databases:
#!/bin/bash
cat <<EOF | sqlite3
ATTACH DATABASE "source.db" as source; -- one billion values
ATTACH DATABASE "dest.db" as dest; -- no pages allocated
INSERT INTO dest.integers SELECT value FROM source.integers;
EOF
For this table SQLite working with its own data structures reaches 10.7M rows/s, unlikely to be exceeded by another method.
This simple table already introduces a wrinkle: SQLite integers are not fixed-width, but stored with a variable-length encoding from 0 to 8 bytes. This implies the distribution of values affects performance, with small values fitting more densely into a page, as would shorter strings. You wouldn't deliberately write a test in which larger test runs used longer test strings, but a similar effect occurs as integers grow larger.
Integer size and insert speed
| Values | Rows/s | DB size, GB |
|---|---|---|
| all zeros | 9,341,000 | 0.90 |
| all ones | 9,508,000 | 0.90 |
| int8 | 8,605,000 | 1.00 |
| int16 | 8,743,000 | 1.10 |
| int32 | 7,952,000 | 1.32 |
| int64 | 7,294,000 | 1.71 |
carray insertion of 100M uniform random integers
Smaller values are faster to insert and the resulting database is smaller.
Applications rarely control these values, but it can bias tests.
Suppose one test generates unique IDs with numbers [0,N), and another samples N
unique values from [0, INT64_MAX]. The contiguous values occupy
more space as N gets large; The sparse set has steady average size.
Combining small values with the fastest insert methods, we obtain even higher numbers:
Inserting two billion bools into a table
| Method | Rows/s |
|---|---|
carray |
10,409,000 |
carray, unsafe PRAGMAs |
10,577,000 |
| bound params, unrolled insert | 8,638,000 |
635 million rows per minute is probably a SQLite record, if you need a database of billions of bools.
SQLite is limited in transactions per second. Use an enclosing transaction for bulk operations. Those with a database mindset already think transactionally, but new users often encounter SQLite as a file writer for shuffling data between systems or within scripts. Because default interfaces execute each insert as a separate transaction, new users are frustrated to discover writing a file this way is literally slower than dial-up.
The next most important step is to reuse a prepared statement and bind new values to it, rather than generating new text each time. The interface for these mechanisms varies by language and library, but tends to look something like this:
auto Conn = sqlite_connection("test.db");
{
// tx object will rollback changes if
// we leave scope without committing
auto Tx = Conn.new_transaction(transaction_mode::deferred);
// keep statement construction outside loop
auto Stmt = Conn.new_statement(R"SQL(
INSERT INTO integers(value)
VALUES (?001);
)SQL");
// loop binds values and executes
for( const auto Value : MyData ){
Stmt.bind_int(1, Value);
Stmt.step();
Stmt.reset();
}
Tx.commit();
}
Following these two basic steps is thousands of times faster than naive usage and is usually good enough:
| Method | Rows/s |
|---|---|
| Separate transaction per row | 429 |
| One transaction, separate statement per row |
522,000 |
| One transaction, reused statement |
2,457,000 |
uniform 32-bit integer insertion
Breaking up a large job into multiple transactions is unnecessary; One transaction can insert a billion rows. One reason you might want to split long-running transactions is to give other database connections a chance to run.
Many databases allow batching to execute multiple statements with a single command, intended to reduce network round-trips. SQLite lacks this concept, as it is an embedded library operating within the calling program rather than on a network server. (Some generic database adapters provide batching for SQLite within their own command system.)
Absent explicit batching, do more work with each statement by inserting multiple rows, with the following syntax:
INSERT INTO integers (value)
VALUES (?001),(?002),(?003);Note commas go between sets of parenthesis, not within
them. (1),(2),(3) supplies three values
for the same column in succession, but
(1,2,3) specifies values for three columns of one row:
sqlite> INSERT INTO integers (value) VALUES (1,2,3);
Error: 3 values for 1 column
sqlite> INSERT INTO integers (value) VALUES (1),(2),(3);
sqlite> SELECT * FROM integers;
1
2
3
We can apply a technique similar to loop unrolling, that may reduce overhead. Modify the inner loop of a bulk insert to bind several rows:
auto NextValue = MyValues.begin();
// assuming statement has five parameters:
for(int i=0; i<N; i+=5){
Stmt.bind_int( 1, *NextValue++ );
Stmt.bind_int( 2, *NextValue++ );
Stmt.bind_int( 3, *NextValue++ );
Stmt.bind_int( 4, *NextValue++ );
Stmt.bind_int( 5, *NextValue++ );
Stmt.step(); Stmt.reset();
}
// if data indivisible by five,
// finish with a single-insert statement
// to handle remaining elements one-by-one
This easy change doubles integer insertion speed. More unrolling has diminishing returns:
Speedup from loop unrolling
| Unroll degree |
Relative speed, rows/s |
|---|---|
| 1 | 1.00x |
| 5 | 1.95x |
| 10 | 2.30x |
| 20 | 2.47x |
100M 32-bit integer insertion
In separate experiments with larger strings and more columns, the benefit of unrolling is less pronounced, the limiting factor becomes writing to disk. Binding many small values also has more overhead.
Someone trying to increase speed will eventually discover the PRAGMA
command's ability to disable safe file operations on a connection, at the
risk of database corruption:
Unsafe PRAGMAs
Conn.new_statement("PRAGMA journal_mode = OFF;").step();
Conn.new_statement("PRAGMA synchronous = OFF;").step();Depending on what you are inserting, the effect of these options varies widely:
Effect of unsafe options on bulk insert speed
| Insert test | Safe speed | Unsafe speed | Difference |
|---|---|---|---|
| 100M 32-bit integers | 5,845,000 | 6,435,000 | +10% |
| 1M 1k strings | 278,000 | 617,000 | +122% |
Prepared statements with 20x batching
Small rows are CPU limited by internal SQLite operations, while large strings fill and write pages faster, slowed by synchronous writes.
It is inadvisable to use unsafe options. Aside from blog posts trying to set speed records, unsafe writes are often considered for storing temporary or test data. I discourage such shortcuts. For controlled results, test setups should be more, not less, robust to weird errors and corruption. Also, one cannot guarantee hasty test code will never be copied or used as reference for production, with the magic go-faster incantations copied as well.
Corruption doesn't mean a database cleanly disappears with a crash, to be rebuilt anew. A corrupt file has unspecified state, and reading it has undefined results. There's a difference in problem severity between the contents of a temp file simply disappearing, vs. being potentially random.
Interaction of sync writes with filesystem
There is a way out of the safety and speed dilemma depending on the platform. The problem is synchronous writes serve two roles:
Allowing an application to wait for assurance a write has gone through all caches and is persistently stored. Used for services that offer a guaranteed signal to clients their request has been permanently recorded.
Acting as a reorder barrier preventing the storage system from moving writes around each other. Needed to implement transactions, by writing out new data blocks, followed by a write making these changes visible to the rest of the system.
The reorder barrier is needed for consistency, can be cheaply implemented by the filesystem, and allows applications issuing the write to continue immediately. Waiting for durable writes is slower, and is unnecessary to prevent data corruption, only last-second data loss. Unfortunately, conventional file APIs combine these concepts, and the synchronous write serves both purposes.
Some storage systems like ZFS have an option to unbundle this - preserve the ordering constraint, but make the write asynchronous, by immediately returning to the requesting application as if the write has been persisted. The database may lose transactions immediately prior to the crash, but will be intact.
Because the performance impact of waiting for persistence is large, services and databases may already be lying to you about writes being "done". Until 2021, the default configuration for MongoDB was to report writes as successful with acknowledgement of a single node, even though they might get rolled back later. This can be a reasonable tradeoff so long as you're aware of it.
carray extensionSQLite has a concept of virtual tables - foreign data sources in the SQL domain represented by a table interface. These tables don't exist as data pages and are backed by C callbacks provided by modules. The interface allows SQL code to homogeneously interact with extensions with the familiar table model, like how virtual file systems allow presenting arbitrary data, like printers or network locations, as browseable folders. SQLite virtual tables can model abstract things like infinite number sequences or the contents of a zip archive.
The official list of virtual tables contains many special-purpose and
debug tools, but hidden among them is the carray() function, an extension disabled by
default. That it is not included is disappointing, as it benefits common
uses.
carray() enables binding array pointers to a statement,
which SQL code can access through a virtual table. This is referenced with a
"table-valued function", a syntax for how virtual tables
accept arguments:
SELECT value FROM carray(?001, ?002, "int32");?001 and ?002 are parameters for the pointer and
number of elements. SQLite has special functions for binding pointers to statements.
Supported types include numbers, strings, and binary objects.
The utility of the carray extension
The canonical use of carray is passing a variable-length
set of values for use with the IN operator:
SELECT data FROM documents
WHERE id IN carray(?001, ?002);Conventional SQL advice for set queries like this is to insert values into
a temporary table, or use dynamic SQL to build up a
WHERE...IN(...) clause with a long list of your values. Both
options are unsatisfying.
With array binding the query is elegant:
vector<string>
sql::get_documents(const vector<i64>& IDs){
auto Stmt = m_conn.new_statement(R"SQL(
SELECT data
FROM documents
WHERE id IN carray(?001, ?002, "int64");
)SQL");
Stmt.bind_array_pointer( 1, IDs.data() );
Stmt.bind_int( 2, IDs.size() );
vector<string> Result;
Stmt.for_each_row([&](auto R){
Result.push_back(R.get_string(0));
});
return Result;
}No query text manipulation or temporary table insert loop to clutter things. Depending on your combination of database, language, and library, support for array binds like this is highly inconsistent.
SELECT from carray works in an
INSERT, too, which I'd never seen before:
INSERT INTO integers (value)
SELECT value FROM carray(?001, ?002, "int64");This is faster than any other method tested, coming within 15-25% of the direct
ATTACH DATABASE copy. Array length is constrained by a 32-bit
integer, so no batching at the statement level is required for large sets.
Larger arrays increase speed all the way to inserting a billion values in a
single statement:
Inserting one billion rows
with array binding
| Rows per statement | Rows/s |
|---|---|
| 1,000,000 | 7,156,000 |
| 10,000,000 | 7,912,000 |
| 100,000,000 | 8,601,000 |
| 1,000,000,000 | 9,310,000 |
carray insertion of 32-bit uniform integers
SQLite is single-threaded, synchronous, and CPU bound here, so going faster is unlikely.
This technique has a huge drawback: It can only practically insert a single
column. This is because each carray use represents a table, and
tables cannot be accessed together without a join on some common field. The
virtual table does contain such a field - the rowid. But, it is
unusable, because though the id is monotonic, SQLite cannot take advantage of
this information as it does not support merge joins of presorted inputs, only
nested loop joins. This prevents the query from zipping along both arrays in
one go.
With these limtiations, a possible use for generating a fast single column
table is document storage. An INTEGER PRIMARY KEY doesn't need a
parameter binding and provides a handle for indexed access to opaque
strings or binary objects, often used for data intake and between
applications.
If you are using SQLite tables as key-value stores, the default
rowid value is unstable and can be changed by some database
operations. Use INTEGER PRIMARY KEY for stable keys usable by an
application.
More about carray access limitations
Even without merge join support, a nested loop join can be fast if the join field is indexed for random access. Consider this simple join:
EXPLAIN QUERY PLAN
SELECT * FROM
a CROSS JOIN b
ON a.rowid = b.rowid;
For CROSS JOIN, SQLite always defers to the
user's table order, which assists in exposition.
This produces a scan on one table with a key lookup for each row into another table:
QUERY PLAN
|--SCAN a
`--SEARCH b USING INTEGER PRIMARY KEY (rowid=?)
This is still fast, and though the key lookup is in principle logarithmic,
accessing indexes in order is cheap thanks to caching, as well as an optimization in
sqlite3BtreeTableMoveto() to avoid tree traversal if
the requested key is one past the cursor's previous position.
Within the carray module, the SQLite rowid is
simply an index into the currently bound array (plus one). A contiguous array
should afford fast random access. But instead, if you ask SQLite to JOIN a
carray table, it gets implemented as a table scan:
EXPLAIN QUERY PLAN
SELECT * FROM
carray(?001, ?002, "int64") AS a
CROSS JOIN carray(?003, ?004, "int64") AS b
ON a.rowid = b.rowid;
4 ,0,0,SCAN a VIRTUAL TABLE INDEX 3:,
11,0,0,SCAN b VIRTUAL TABLE INDEX 3:,The carray extension is loaded with
the C API, so the output looks different from the CLI.
This is by design. During query planning, SQLite asks each table
questions about what indexes it has available to access columns by particular
constraints. The Carray extension is simple and doesn't report it has
random access by rowid. The only access it implements is
rewinding a cursor to the start of the array, then incrementing it one step
at a time. This could probably be changed to support random access by
rowid, and give the query planner the ability to work with more than
one carray() table in the same query.
WITHOUT ROWID tables and INTEGER PRIMARY KEYSQLite has another option that appears to offer faster inserts, but turns out not to.
All SQLite tables are clustered index tables. Even a one-column SQLite table
has two values per row: the column data, and a key value used for locating the
row within the table B-tree. By default, this key is a 64-bit integer, the
rowid. If we're only inserting integers anyway, can we remove
this?
A primary key on a SQLite table is implemented as a secondary index on the cluster table. Primary key lookups are doubly indirected; A first tree traversal maps the user key value to a rowid, and this rowid is the key for a second lookup into the primary table to obtain the row data.
Because adding an indirection to index accesses is slow, SQLite later
added the
WITHOUT ROWID option to merge the role of the cluster key and
the primary key; The table is keyed by the user-specified primary key
without a separate rowid.
A downside is the primary key must be unique. For fast inserts, the bigger
problem is the values being inserted are now all indexed, and so the random
index access penalty applies as described below. So
fast bulk insert values need to not only be unique, but presorted. This is a
truly impractical scenario, but one irrelevant for speed games anyway, as
WITHOUT ROWID variations are slower.
A table using WITHOUT ROWID or INTEGER PRIMARY KEY
(similar optimization) occupies less space. But despite being smaller, both are
slower to insert to:
Effect of table type on user key insertion
| Table type | Insert speed, rows/s |
Size, MB |
|---|---|---|
| default rowid | 8,757,000 | 1,331 |
INTEGER PRIMARY KEY |
4,248,000 | 861 |
INT PRIMARY KEY WITHOUT ROWID |
3,108,000 | 974 |
carray insert of integers 0..100M
Without being an expert in SQLite VM bytecode, it looks like these two alternatives are doing more work on inserts:
Comparison of insert bytecode instructions
Output of: EXPLAIN INSERT INTO integers (value) VALUES (1);
Rowid table
Init
OpenWrite
Integer
NewRowid
MakeRecord
Insert
Halt
Transaction
GotoInteger primary key
Init
OpenWrite
SoftNull
Integer
NotNull
NewRowid
MustBeInt
Noop
NotExists
Halt
MakeRecord
Insert
Halt
Transaction
Goto
Without rowid
Init
OpenWrite
Integer
Null
HaltIfNull
Affinity
Noop
SCopy
MakeRecord
NoConflict
Halt
Integer
Insert
IdxInsert
Halt
Transaction
Goto
The default rowid table always uses a dedicated instruction to get the next rowid value. The alternatives must check if the user-supplied key is null, which each handles differently. They must also check the key against the existing index for uniqueness. Because SQLite is already CPU-bound in these extreme insert tests, the extra VM operations are costly.
These table options are smaller and I expect reading from them to be faster. But they're not a way to get fast inserts.
SQLite performance is inhertently limited because all tables are clustered tables, with data stored in the leaf nodes of an ordered B-tree. This is unfortunate if you want an unordered heap table, such as a temporary table for batch data intake.
Given that you're stuck with a cluster key, SQLite has three different ways to generate it:
rowid is an increasing integer index not
guaranteed to remain stable over time.
INTEGER PRIMARY KEY adds the guarantee keys are
stable, although deleted keys may be reused. It uses no more space
and is implemented as an alias for the rowid.
AUTOINCREMENT is an option to the INTEGER
PRIMARY KEY adding the guarantee of no key reuse.
Most applications only need INTEGER PRIMARY KEY, which does not
appear to be slower (as long as SQLite is generating the key for you). Use of
AUTOINCREMENT is discouraged by the SQLite authors for performance reasons,
although the effect in this simple test is small.
Effect of automatic key type
| Table key | Insert speed, rows/s |
|---|---|
default rowid |
8,183,000 |
INTEGER PRIMARY KEY |
8,224,000 |
AUTOINCREMENT |
7,784,000 |
carray insertion of 100M uniform 32-bit integers
All tests so far involve tables with no indexes. A large unindexed table is suitable for sequential access, or access by the automatic primary key. Outside of testing or data loading, most uses have indexed fields or program-supplied IDs, and the pattern of the index keys dominates.
All SQLite tables are clustered B-tree indexes, and inserts always pay some
index penalty. For tables with no user indexes, the automatic index on
rowid or INTEGER PRIMARY KEY is modified in ascending
order, which is least burdensome. Deviating from ascending order has a cost,
but programmers often lack intuition about how much. Experiments with many key
patterns reveal some guidelines. The quick lesson is to avoid random
index insertion order as much as possible:
Effect of key sequence on indexed insert speed
| Key pattern | Example | Remarks | Insert speed, rows/s |
|---|---|---|---|
| Sequential | 1,2,3,4,5 | Inserts at end | 3,030,000 |
| Reversed | 5,4,3,2,1 | Inserts at beginning | 1,534,000 |
| Shuffled | Inserts everywhere | 161,000 | |
| Outside-in | 1,10; 2,9; 3,8; | Inserts at middle | 1,458,000 |
| Inside-out | 8,3; 9,2; 10,1; | Inserts at opposite ends | 1,529,000 |
| Odds-then-evens | 1,3,5; 2,4,6; | Inserts at end, then makes ascending pass | 2,857,000 |
| Odds-then-evens, reversed | 6,4,2; 5,3,1; | Inserts at beginning, then makes descending pass | 1,488,000 |
| Sawtooth | 0,10,20; 1,11,21; | Inserts at end, followed by nine ascending passes | 1,116,000 |
carray insertion of 5M keys
From these results we observe:
Ascending access is cheaper than backwards. I believe this is from an optimization in the SQLite B-tree seek to avoid tree traversal if the requested position comes immediately after the current cursor. This optimization only checks for ascending order, not descending.
Inserting to the middle has no overhead relative to inserting at the ends, as long as the locality is the same. I suspect when people think inserting in the middle is slow, they're really observing the cost of random index access, touching many different locations, rather than repeatedly accessing the same interior locations.
Page splits are relatively cheap, as long as they're in cache. More ascending insert passes have low marginal cost despite splitting many existing pages.
Randomness is the costly factor. Index inserts are fast when few pages are touched at a time, keeping them in cache. Inserting to a handful of "hot" positions in the tree is cheap no matter what those positions are. The slowness comes from accessing many different locations in the index.
These results also show why, contrary to common advice, increasing SQLite's page cache doesn't always benefit bulk inserts. Inserting ascending keys incurs little cache pressure. An index on a random and unsorted field, like a filename or email address, uses cache inefficiently.
Effect of page cache size on index insert speed
| Key pattern | Insert speed, rows/s | ||
|---|---|---|---|
cache_size=2000 |
4000 |
2000000 |
|
| Sequential | 4,202,000 | 4,292,000 | 4,348,000 |
| Random | 306,000 | 400,000 | 988,000 |
carray insertion of keys 0..10M,
INTEGER PRIMARY KEY table
In the above example, the gain from a big cache on sequential insertion is barely measurable. Random insertion benefits from a larger cache, but uses it inefficiently, and only gets to a fraction of the speed of the sequential insert. It can be made several times faster if we increase the cache to the point where the entire database fits into memory. This is only feasible in a trivial example with no other row data to fill up the database.
UUIDs or hashes are slow as table keys because of a random access penalty. Inserting these into an index has poor locality.
Because sorting in an application is usually faster than in the database, presorting records by an indexed field speeds up inserts. This is only possible for one index at a time; If multiple indexed columns are uncorrelated, only one can be optimized.
Interaction of random key insertion and caching
In early experiments with random key order, I was surprised by test times increasing quadratically with N. Expanded tests on larger tables show this behavior transitions to linear:

This speed transition is typical of caching. As the table becomes larger than the cache, random access cost increases, as proportionately fewer pages are in cache. Consequently, total insertion time increases faster than linear by number of elements. In tables much larger than the cache, random access cost approaches a constant factor, as effectively all accesses are misses.
More about B-tree insertion
B-tree index behavior is the subject of myth and apprehension. Some comments assume insertion into the middle of the tree is more costly, because of more splitting and reshuffling occuring, just as inserting into the middle of an array is costly. Others assume the opposite, that inserting at one end of the tree is uneven, and incurs more active "rebalancing" of elements to keep the depth or density of the tree uniform.
Neither property applies to B-trees; As we observed, average insertion cost is uniform throughout, and insertion "hot spots" are harmless. The only access penalties are imposed by the underlying page cache, which favors locality of access.
To "appreciate the full beauty" of B-tree insertion, as Knuth says, understand their growth is not outward like conventional trees, but inward, with leaf pages splitting to accommodate insertions, and these splits propagating as necessary from the leaves to the root, a procedure that "neatly preserves all of the B-tree properties."
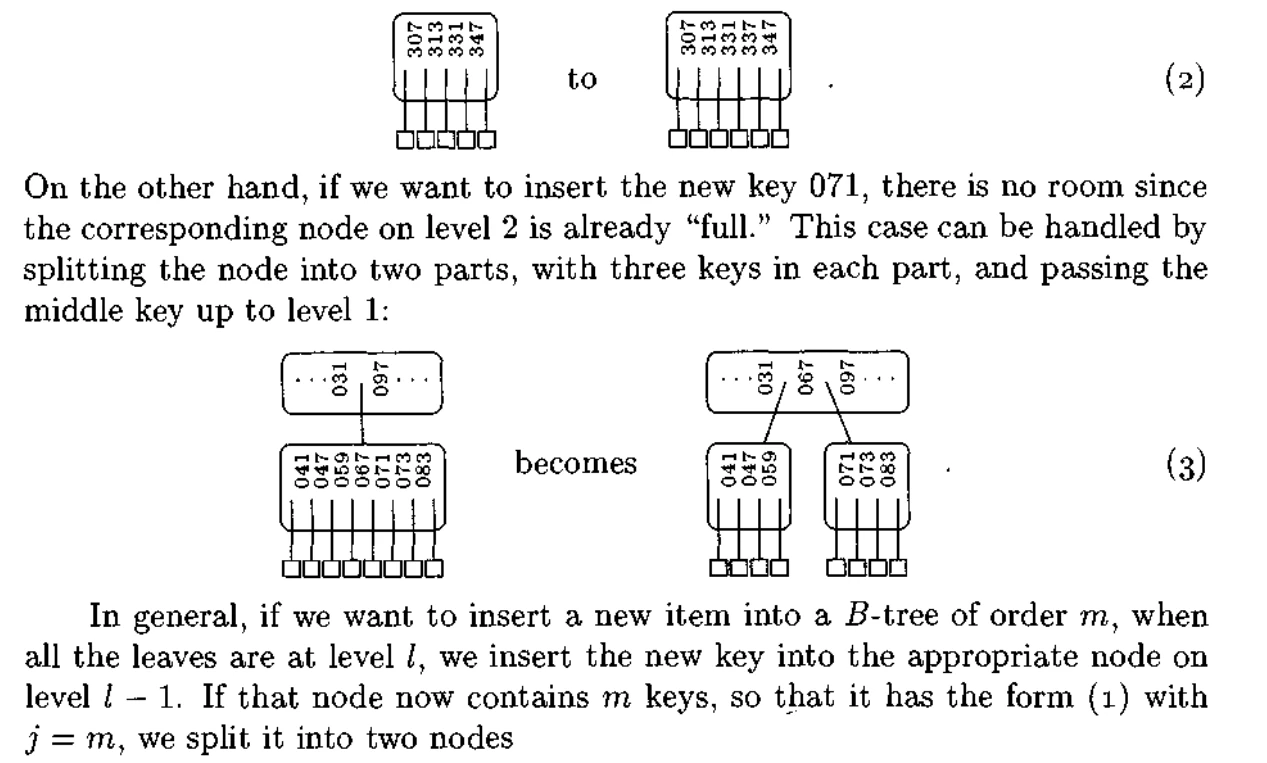
Description of B-tree insertion from Knuth's Art of Computer Programming, Volume 3 (1973)
Think of B-tree growth not as links appended to the fringes of a tree, but as a pyramid, wider first at the base, then upward, until a new capstone is placed at the top. Because new layers are created only by root splits, the depth of the tree is always uniform throughout. To borrow a phrase from Jeff Bonwick, this balancing is not automatic, so much as it is implicit.
A B-tree operation sometimes called rebalancing exists, but it is more properly termed defragmenting. The rebalancing is not of depth, but occupancy, and arises not from inserts, but deletions, which leave free slots in the leaf pages. If deletions are high or uneven, this space can be reclaimed and the index consolidated, but by default databases including SQLite will not do this automatically.
Another recommendation for bulk inserts is to insert into an unindexed
table, then create desired indexes on the completed table. Theree are no truly
unindexed SQLite tables; All tables are clustered indexes on at least
the hidden rowid. We don't think of them as slow like a
user-defined index becasue the rowid insertion is usually monotonic, the
fastest way to insert into an index.
Example index definition
CREATE TABLE integers (value INTEGER);
CREATE INDEX idx_integers_value ON integers (value);The above table is represented as two B-trees: A
primary table keyed by rowid, and a secondary index keyed by value
for rowid lookup into the primary table.
I didn't expect postponing index creation to be much faster. For unordered data, access is random either way. But it turns out creating an index after inserting data is several times faster:
Indexing before or after insertion
| Order | Total speed, rows/s |
|---|---|
| Index before | 293,000 |
| Index after | 963,000 |
| Index before, with sorting in application | 2,123,000 |
carray insertion of 10M uniform 32-bit integers
It's still slower than an unindexed table, but much improved. This is because during index creation, before inserting values into the index tree, SQLite presorts them, turning random access into sequential access:
Index creation bytecode instructions
sqlite> EXPLAIN CREATE INDEX idx on integers(value);
addr opcode comment
---- ------------- -------------
/* setup code omitted */
12 SorterOpen
13 OpenRead root=2 iDb=0; integers
14 Rewind
15 Column r[10]=integers.value
16 Rowid r[11]=rowid
17 MakeRecord r[9]=mkrec(r[10..11])
18 SorterInsert key=r[9]
19 Next
20 OpenWrite root=1 iDb=0
21 SorterSort
22 SorterData r[9]=data
23 SeekEnd
24 IdxInsert key=r[9]
25 SorterNext
/* cleanup code omitted */
The sorting operation uses a special temporary index type that avoids random access; It remains internally unsorted until a later opcode invokes the sort operation in preparation for reading. The first loop builds the index entry for each row and inserts it into the sorting table. Only data needed for the index is sorted, not the entire row. Because this is a secondary index on a clustered table each entry is a pair of (key, rowid) providing indirect access into the primary table. The actual sorting occurs all at once with a special instruction at the beginning of the second loop, whose body inserts the sorted rows in optimal order into the final index.
This extra sort step is faster than incrementally inserting each value into the index as it comes in. But having SQLite sort data for you is slower than doing it yourself; If you presort records in your application, they arrive at the database in an order favorable to incremental indexing. This is twice as fast as delayed indexing, but it's only possible to presort by one field at a time.
A downside of delayed indexing is it requires inserting all table data at once. Presorting in your application speeds up inserts into an existing indexed table. It would be neat if the database always used this sorting-on-the-side trick when inserting multiple rows into an indexed table, to make them equally fast. But complications could make this impossible, such as interactions with triggers in inserts.
Unsurprisingly, larger strings occupy more space and are slower to insert. But, reduced per-row overhead means they're more efficient, with more application data written per second, eventually saturating the system disk. If you have a choice, and need throughput, store larger chunks of data in fewer rows.
Effect of string size on insert speed
| Length | Rows/s | MiB/s | |
|---|---|---|---|
| 4 | 7,874,000 | 30.04 | CPU limited |
| 16 | 6,993,000 | 106.70 | |
| 32 | 5,208,000 | 158.95 | |
| 64 | 3,704,000 | 226.06 | |
| 128 | 2,342,000 | 285.88 | |
| 256 | 1,610,000 | 393.14 | |
| 512 | 1,047,000 | 511.29 | Disk limited |
carray insertion of 10M pregenerated
char* strings
If an application has lists of values, that are accessed as a unit and whose contents are unindexed, consider concatenating them for storage and separating them in the application.
Most tables have multiple columns. If you have a choice, is it better to have more columns, or fewer? The answer is mixed:
Column count and insert speed
| Table data | Rows/s |
|---|---|
| 1 column x 1024 chars | 221,000 |
| 2 columns x 512 chars | 234,000 |
| 4 columns x 256 chars | 248,000 |
| 8 columns x 128 chars | 206,000 |
| 16 columns x 64 chars | 184,000 |
Basic bound parameter insert. The benefit of unrolling is smaller for large rows.
The fast carray insert
method is impossible with multiple columns.
A penalty applies for larger strings, and for more columns.
In the previous section we saw more data
per row is efficient. But this doesn't necessarily apply to storing data in fewer columns.
For each insert, SQLite does a printf
style preparation of the row data to be inserted into the table, with special
handling for large data which overflows onto additional pages. Binding
more columns has overhead, which is maximized when many small values are bound.
Large rows are limited by the rate pages are filled and written to disk.
Although potential optimization exists for the number of columns for heavier data,
it's less important than overall data size and any index overhead.
In a 2021 blog post, Avinash Sajjanshetty experimented with generating a 100M-row table with the following schema:
create table IF NOT EXISTS user
(
id INTEGER not null primary key,
area CHAR(6), -- any six digits
age INTEGER not null, -- one of 5, 10, or 15
active INTEGER not null -- 0 or 1
);
Based on all the previous tests, without any control over the schema, we know we want to:
Do everything in one transaction
Insert multiple rows per statement
Have the database generate the id for us
Use unsafe writes if permitted
Increase cache size
One question left unclear by the post is whether the time should be purely insertion speed, or the data generation as well. Generation of random data often takes longer than inserting into the database. With no validation, or concern for RNG quality, why randomly generate anything? Insert "123456" repeatedly, and bind no data at all. But that feels like cheating, so we'll try a few combinations.
Start with constant data to maximize row output speed:
INSERT INTO user (area, age, active)
VALUES ("123456", 5, 0),
/* ... */
("123456", 5, 0);
Then, replace literals with parameters, bound with constant data, to measure the overhead of parameter binding:
for( int i=0; i<N; i+=20 ){
for( int j=0; j<20; ++j ){
Stmt.bindText((3*j)+1, "123456");
Stmt.bindInt( (3*j)+2, 5);
Stmt.bindInt( (3*j)+3, 0);
}
Stmt.step(); Stmt.reset();
}
After this, replace the constant parameters with random data:
for( int i=0; i<N; i+=20 ){
for( int j=0; j<20; ++j ){
Stmt.bindText((3*j)+1, random_string(6));
Stmt.bindInt( (3*j)+2, random_from(array{5,10,15}));
Stmt.bindInt( (3*j)+3, random_number(0,1));
}
Stmt.step(); Stmt.reset();
}
Best speeds with mixed data test
| Insert method | rows/s |
|---|---|
| Constant data, no binding | 6,130,000 |
| ... unsafe | 7,673,000 |
| Constant data, bound | 3,732,000 |
| ... unsafe | 4,307,000 |
| Random data, bound | 2,851,000 |
| ... unsafe | 3,258,000 |
20x unrolled inserts of 100M rows
The best speed for a real database file reported in Avinash's repo is about 4.3M rows/s with unsafe options. Without any adjustments for our different hardware, this sounds about right. With worse RNG, or optimized data generation, our random data test would approach the constant data version, which also got 4.3M rows/s. But that's outside the scope of a database test.
Results show a significant cost imposed by binding dozens of parameters for each statement. I hoped array binding could overcome this, but the join limitation limits their use.
The important tips are:
Use a transaction and parameterized queries for the biggest gain over naive usage
Index after bulk insertion on new tables when possible
Insert multiple rows per statement if you need to faster bulk inserts
Don't change PRAGMAs from default unless you know what you are doing; Increasing page cache size can be helpful
Insert speed games are revealing of database performance characteristics, but are themselves impractical. The fastest tests all involve insertion into unindexed tables. As soon as indexes are applied, their costs dominate.
Rapidly inserting millions of unindexed rows is only useful when later read sequentially, perhaps as part of a data pipeline. A SQLite format does add some conveniences for this role, but if you are trying to emit rows as fast as possible, consider the database only sinks integer rows at a rate of about 40 MiB/s; In comparison the same computer's unremarkable SSD has a sustained write rate of 454 MiB/s for regular files.
The disparity is even greater for tests setting records for generating in-memory SQLite databases. Using SQL to operate on temp data is convenient, but if you want to append rows to a table in-memory, other tools are faster. Our test programs start by generating random numbers in an array at a rate of 362 million values per second, or 2.70 GiB/s, with no optimization at all. We then contrive the fastest possible method for inserting these rows into a database at a meager 5-10 million per second, and once they're in they are extremely slow to operate on.
If you want a fast in-memory table, consider Boost.MultiIndex, a C++ template container similar to a database table with multiple indexes. If you have several indexes on a table this can be easier than maintaining your own container with separate lists/sets/maps referring to elements in it.